“An oath to LLMs, I hereby declare,
That this limerick is my only affair,
All content below, be aware,
Is purely human, and beyond compare,
No AI inputs, truth we shall bear.”
These concerns align very well with our Platform Principles, addressing the needs of our key enterprise stakeholders.
- Business users- both for control during the design stage, and in managing operations in production.
- Power users- who seek direct access to the underlying engine for specific customizations, thereby seeking to extend the automation frontier.
- Addressing enterprise concerns about data privacy, and integration into the broader enterprise landscape
We are launching the upgraded version of our CMR+ platform with enhancements related to fine-grained confidence scoring, channel breadth, seamless integration with enterprise platforms, and addressing enterprise-grade needs. Along with this, we are also incorporating capabilities leveraging Generative AI, in alignment to the above Platform Principles. Our current automation framework is designed to follow the step-by-step logic approach taken by humans. LLMs fit very well within the same automation paradigm, both during design and during the feedback process.
- Extraction capability from a variety of information representation layouts (tables, paragraphs etc.)
- Synthesis of content along predetermined data areas based on the semantic meaning of the content. This includes summarization, intent classification and gauging user sentiment.
- Reasoning based on a combination of inputs from the documents and other enterprise data
- Conversational Layer creation to access information from both within and across documents- at all times through the document life-cycle, starting from initial configurations to the final output.
These concerns align very well with our Platform Principles,
addressing the needs of our key enterprise stakeholders.
- The CMR+ platform architecture includes an abstraction layer that allows business users to make configurable decisions. This includes a decision on using capability on-premise vis-à-vis options of cloud models across data-jurisdictions. This abstraction also allows flexibility to optimize costs and make run-time decisions, based on individual documents. Furthermore, this allows for a standardized data interface to ensure processes downstream, are not impacted by any change to the models invoked.
- The Platform has adequate guardrails available to control the data being sent to third-party applications. These could take a variety of forms inclusive of controls on the size of the document section being sent, redaction and anonymizing of identifiable information, and controls on content generated from the language models.
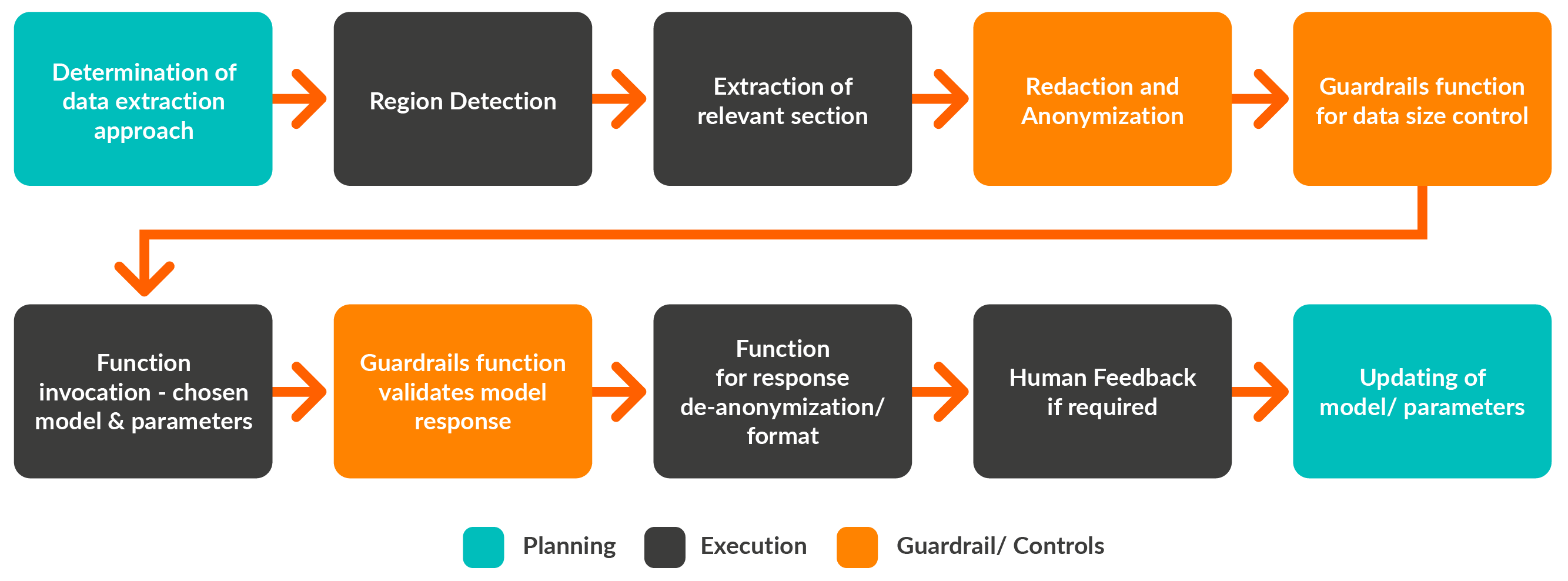
Capability development using Large Learning Models
1. Content Extraction Capability
As examples, we can look at two extraction scenarios :
a) Paragraph Extraction
Extraction from paragraphs can be quite challenging, without a good semantic understanding of the data. Data may be represented in many different ways, making it difficult to identify and isolate the relevant content. The presence of other similar data may amplify the challenge.
In the sample use case below, the data sought was the ‘Liability’ field from a 15- 50 page commercial insurance policy. This information is located anywhere in the document and also expressed in various ways based on the insurer.
Here, CMR+ isolates and identify the paragraph and extracts the contents as-is. This extracted data is sent through the redaction engine, to remove any personally identifiable information.
The CMR+ prebuilt connector would then take this data to the configured LLM with a pre-engineered prompt, the response is presented to the user. The user is able to verify the data in the CMR+ Quality Assurance screen and can provide feedback, which is relayed back for further engineering the prompt.

b) Understanding of Nested Content within Tables
In the use case below, multiple fields are available as a part of the ‘Description’ column, needing that typically needs customization for extraction.
This extraction was achieved without the need for customization through the following steps:
- Identification of the specific area of table content from overall document through CMR+
- Redaction function examines and handles sensitive information.
- Invocation of the Table Extraction LLM function with specific parameters, along with clear definition of output structure.
Results from the extraction function:
{
"ItemsList": [
{
"Unit": "778028",
"Description": "53' AIR RIDE DRY VAN",
"VIN": "1DW1A53268S064738",
"Amount": "$365.21",
"Monthly": "$345.2 ",
"EstimatedMileage": "1000 x $.02 = $20.00"
},
{
"Unit": "567890",
"Description": "54' AIR RIDE FREIGHT",
"VIN": "2DW3A54563468S064738",
"Amount": "$390.46",
"Monthly": "$195.23 ",
"EstimatedMileage": "900 x $.02 = $18.00"
}
]
}
2. Synthesizing Content
- Reviewing legal contracts for force majeure provisions and comparing them against a standard approved language.
- In the customer service domain, is categorizing incoming emails and routing them to appropriate work queue. Additionally, we can also sense the customer mood for usage not only as an input for prioritization, but also for enriching the customer profile to guide life cycle decisions.
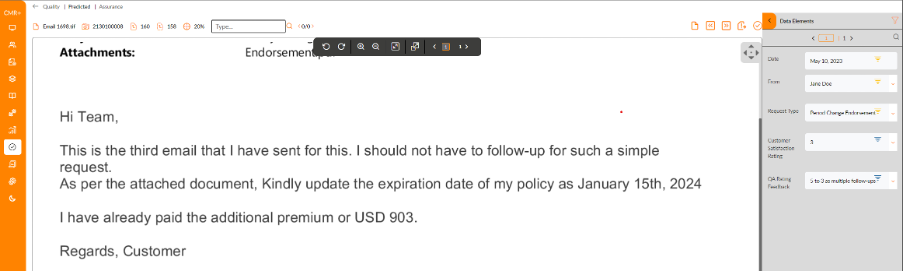
- In this case, the insurance customer had sent an email to the customer service department of her insurance provider asking for the change in policy date to be endorsed.
CMR+ functions extracted critical information including as policyholder name and original policy date, and the Content Analysis LLM function identifies the queue to be “Policy Change Endorsement” for handling this. The function also shared the satisfaction level of the customer as a ‘5/10’- indicating a neutral sentiment. The QA user had changed that to 3/10, with a feedback comment stating, ‘multiple follow-ups’. This will be fed back to tweak the underlying prompt for the Content Analysis LLM function.
3. Reasoning
Moving further from extraction and synthesis, an interesting application is to gather insights from a combination of information embedded in documents, along with other data sources.
A key feature of Reasoning is a multi-stage approach to break the overall question into its constituent elements as a series of steps. This is referred to as “chain-of-thought” and has demonstrated improved performance in our tests. This is close to human reasoning, and also provides traceability around the approach taken.

In this example, the pricing of a product in an enterprise context could have multiple rules applied, including a volume-based pricing schedule, exceptions based on regions and promotional deals linked to specific commitments. The approach entails the following steps:
- Extraction of relevant data from the document
- Lookup both on public domain sources and on proprietary databases, for related details
- Performing reasoning operations/ identify inherent ambiguity and if relevant, present to a decision-maker.
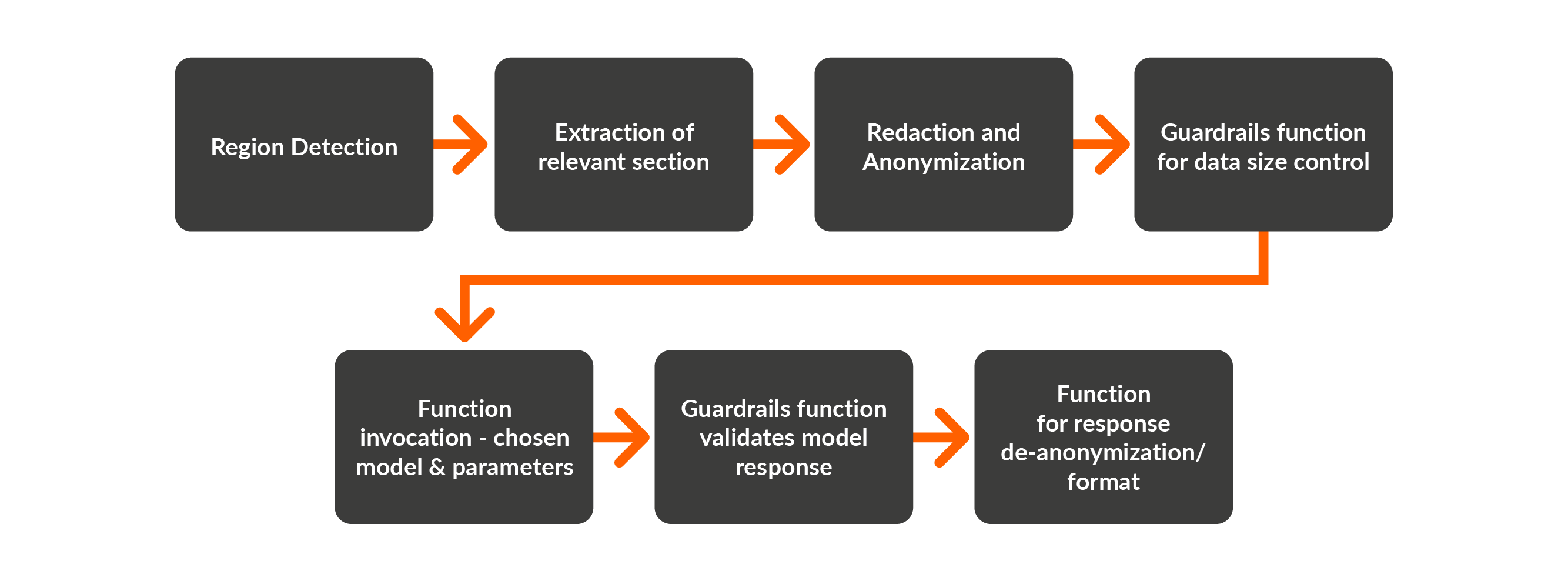
This is fashioned as a multi-stage chain-of-thought logic laying out the steps. The key logical elements, that would enable the Reasoning Function to perform, include
- Identify the territory to which the deal is assigned to. Based on design, this might query online or a local proprietary database
- Calculate pricing based on territory and slab. This would require the split of volumes onto different slabs and pricing per slab.
- Calculation of overall amount, based on the aggregation of slab-wise pricing.
- Determine the incremental value over threshold. If the amount is over the threshold, apply the discount.
- Build a scenario to check if the customer might benefit from a slightly higher purchase amount, based on the discount.
- Present result with logic-steps to the user for model transparency
4. Conversational Layer Creation
Finally, we envisage ability for users to “converse with the documents” at three stages.
- Support the configuration through a natural language mode and creating the required configuration for the underlying engines to process. This might also enable the user to interactively optimize the configuration.
- Enable the QA process with the user guiding the engine with additional inputs for improved performance. As an example, the QA user could offer the suggestion “check the Table with a name like Company Background or Corporate History. Also, Incorporation Date is referred to by column headers DOI or Incorporation”.
- Support end-user queries with a conversational interface that can apply to a much larger data set across enterprise data. As an example, the user could ask “How does the Loan-to-value ratio offered in this mortgage underwriting, compare with other underwritings in the same county and credit score range”. By using embedding techniques that convert the extracted data into a searchable graph, it can be ensured that the responses are restricted to enterprise data. However, this warrants discussion around costs at scale, data privacy, and deployment location.
In conclusion
The Generative AI space is fast evolving and given the rate at which model performances have improved, any long-range planning should factor in continued algorithmic enhancements and new capabilities, Customer expectations are also maturing with conversations around IP rights, and data controls becoming mainstream. Regulators are also rapidly catching up and it is expected that compliance and risk management ecosystem will have greater clarity over the next few years.
Our focus continues to be around supporting enterprise needs around digitizing their critical business processes. -We approach this by creating a foundation for enterprises to unleash their creativity through the right choice of technologies, effective orchestration, and much-needed guardrails. A key focus area is to develop specialized language models that are both compute-efficient and easily trained for specific contexts. While our current focus remains on text, we aspire to become more multi-modal in our approach over time.
While we will continue to drive innovation in line with our product principles, we thought it might be useful to our perspectives based on our interaction with various ecosystem stakeholders:
Business Leaders, along with a better appreciation of capabilities, also need to be informed on inherent limitations. We recommend closer engagement with the space, to assess suitability and if relevant take steps to foster innovation. There might be a need to start considering changes to their current talent pool, operating model, and potentially data-related contractual obligations.
Solution architects and configurators would need to get more hands-on to have greater clarity- and separate the hype from meaningful capability. It is critical to get under the hood to understand both the benefits and risk to make a considered decision.
Automation product ecosystem: While this is a transformative tool for enterprises, it is important to structure this in a manner that can be leveraged effectively.
Given that we started with a limerick, I felt that we should sign off with a positive outlook
“The best way to predict the future is to create it.” – Abraham Lincoln
If you found this blog valuable, contact us to learn more about how we can automate your document processes.
To arrange a demo, simply click the button below.
