You might be aware that in the vast sea of insurance documents, approximately 80% of valuable information is hidden within unstructured text. Imagine both the time and resources that insurance companies spend sifting through policies, claims, and customer correspondence, searching for details like policy numbers, claim details, and beneficiary information. There is additional complexity with this unstructured data being across multiple formats (PDFs, images, emails, word documents and excel), sizes (ranging between a single page and up to 800 pages, 10 excel tabs) and channels (emails, file folders, online interfaces). The sheer volume of data and varieties of its formats overwhelms traditional methods, leading to delayed processing times, inaccurate assessments, and frustrated customers.

The Insurants Entity Extraction solution drives transformation where it automates the extraction of key entities, such as Company and Individual names from claim and policy related documents. Importantly, the system captures coordinate details for the entity names which results in all captured data being highlighted for a simple quality check experience for the user. This level of explainability and enhanced user experience is critical in a world where Large Language Models can generate interesting output but do not provide the certainty and auditability that enterprises require.
Insurance companies and the supporting ecosystem can unlock a wealth of insights embedded within claim and policy documents, enabling more accurate risk assessments and proactive decision-making. By swiftly identifying patterns and anomalies within extracted entities, insurers can mitigate risks, efficiently perform sanctions checks, detect potentially fraudulent activities, and optimize operational efficiency. Ultimately, the adoption of the solution not only streamlines claims and risk management activity but also strengthens customer relationships, positioning insurers as trusted partners in risk management and enhancing their competitive edge in the insurance market.

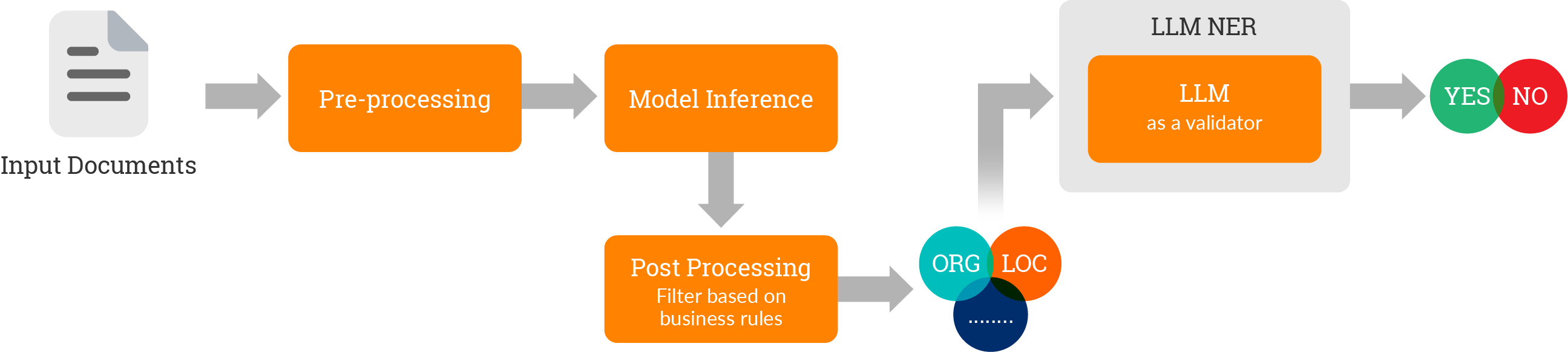
1. Document intake
A document with any input formats(emails, pdfs, tiff, excel) with various layouts and formats can be ingested to the application. The ingestion could be scheduled with a defined frequency or through a priority queue, through external APIs or from cloud storage as well.
2. Core module
The core module comprises of a Named Entity Extractor based on BERT and trained with proprietary insurance data. This is further extended with LLM capability, as a validator to enhance precision and reduce the risks of false positives.
3. User Interface for Quality analysis
The extracted information is highlighted on the actual document. This enhances the experience of a quality user by showcasing from where the results are generated. The user can add entities just by rubber-banding if a specific entity is not extracted.
In this document, we focus further on the named entity recognition (NER) module which drives significant improvement in the performance of the solution.
What is NER?
The term Named Entity was first proposed at the Message Understanding Conference (MUC-6) to identify names of organizations, people and geographic locations in the text, currency, time, and percentage expressions. Since then, there has been increasing interest in NER and IE techniques on text-based data across business domains.
NER is a Natural Language Processing (NLP) based technique to identify mentions of rigid designators from text belonging to semantic types such as a person, location, organization etc. In the insurance domain, these entities typically include various terms and phrases crucial for insurance operations, such as policy numbers, claim types, insured individual’s names, dates, locations, insurance product names, and other relevant terms specific to insurance policies and claims documents.
The Insurants entity extraction solution is with Transformer architecture that extends the power of Large Language Models (LLMs) built on top of proprietary insurance corpora. NER algorithms used employ sophisticated techniques to analyze the linguistic features of insurance data, including lexical, syntactic, and semantic patterns. The algorithms leverage machine learning models, such as statistical models – CRF (Conditional Random Fields), deep learning architectures (BiLSTMs, Transformers), hybrid approaches combining rule-based and statistical methods and Generative AI models
Insurants Solution Architecture implemented
1. Model Training
The core module of the architecture is Insurants NER extractor and validator, and it is based on BERT model and leveraged by LLM. The BERT model is trained with Insurants proprietary data. The validator module extends LLMs in-context learning feature where the LLM is trained through prompts. Training module generates Insurants NER model.
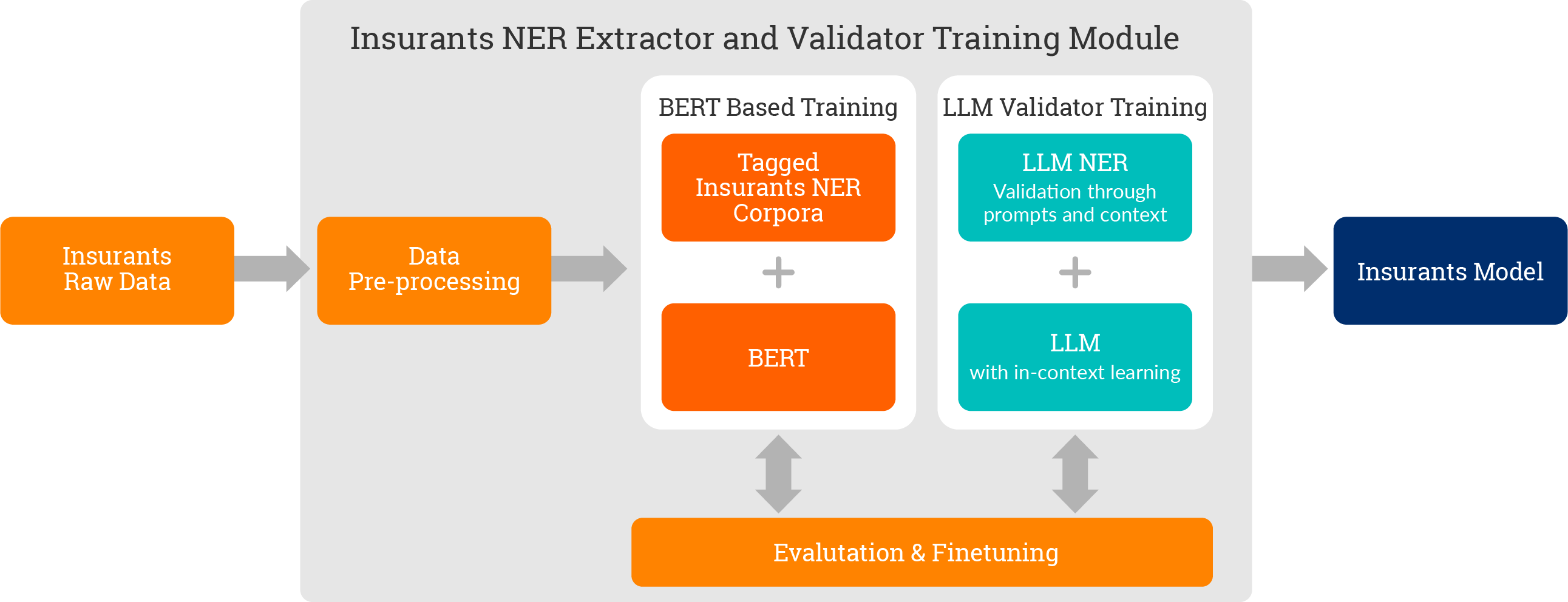
2. Prediction
The core module of the architecture is Insurants NER extractor and validator, and it is based on BERT model and leveraged by LLM. The BERT model is trained with Insurants proprietary data. The validator module extends LLMs in-context learning feature where the LLM is trained through prompts. Training module generates Insurants NER model.
Step #1: Data Preparation or collection
The first step in training any deep-learning-based model is to prepare the data. Normally every solution leverages annotated/labelled data that is publicly available. We have created a dataset from scratch based on commercial insurance documents. In terms of the number of annotations, for a custom entity type, say insurance terms we have observed good results with as little as 200 annotated examples.
The advantage of using the BERT language model is that we trained it not just on sentences having the entity of interest but also on the entities themselves. For instance, for an organization tagger, we train the model on just the names of organization alone in addition to their mention in sentences. Since BERT produces words using sub-words, we leverage the knowledge from single entity mentions generalizing to other entity instances that share the same sub-words.
Step #2 Data augmentation- Building a proprietary dataset for insurance corpora.
As part of the data set creation, our experts have manually annotated 100 policy samples based on the gold standard. These samples are used as base data to augment further. With the help of Generative AI, we generated the required data for training.
Step #3: Data Preparation for model finetuning
The model uses a specific tagging scheme. This is because we train named entities rather than individual words. Alternately of tokens referring only to classes, such as “organization” “location”. They are prefixed with the information where a phrase like “B” or “I” stands for “beginning” and “inside.”
For example, consider the name ‘Celtic Corporation’; this would be tagged as (B-ORG, I-ORG), meaning (organization, organization). This technique is known as the IOB (sometimes BLUE) format. However, we have not built special classes for these. Additionally, a few things also taken care of, such as case sensitivity, special characters and spacing of words, and turning the first letter of every uppercase letter. These small things led to higher accuracies and made the model more generic for other datasets.
Step #4: Parameter Tunings
In step three, we load the BERT model and initialize the hyperparameters. However, finding the proper parameters right at the start is difficult. We fine-tuned it based on how the model performed on our data. Also, in this step, we loaded the labelled data as tensors for training them.
Step #5: Training BERT Model
The pretrained language representation can be applied to downstream NLP tasks in two ways using:
(a) A fine-tuning-based approach
This is minimally dependent on task-specific parameters, i.e., training was performed over downstream tasks while fine-tuning the pretrained parameters.
(b) A feature-based approach
In this, task-specific architectures, including pretrained parameters, were used as additional features. However, during pretraining, the same objective function is used by both approaches, in which language representations are learned using unidirectional models.
The BERT model uses the “Masked Language Model” (MLM) and “Next Sentence Prediction” (NSP) pretraining objectives, which mixes the left and right context, allowing the pretraining of a bidirectional deep transformer while removing unidirectional constraints.
We implemented a fine-tuning-based approach, which used already-pretrained models. The pretrained model is further trained on a proprietary insurance corpus to fine-tune the parameters.
Step #6: LLM as a validator via in-context learning
During in-context learning, we provided the LLM a prompt that consists of a list of input-output pairs that demonstrate a task. At the end of the prompt, we appended a test input and allowed the LLM to make a prediction just by conditioning on the prompt and predicting the next tokens. To correctly answer the prompts, the model needs to read the training examples to figure out the input distribution, output distribution, input-output mapping, and the formatting.
The validator module is optional. This helps in improving the precision of extracted contents as an additional layer of validation is enforced on extracted contents.
Example
The given sentence: Directors and Officers liability is a coverage type offered by insurance companies.
Is the term “Directors and Officers” in the given sentence an organization entity? Please answer yes or no
No
The given sentence: MetLife is one of the largest global providers of insurance and annuities.
Is the word “MetLife” in the given sentence an organization entity? Please answer yes or no
Yes
Step #7: Estimating Accuracy of Insurants Entity Extraction Model
We estimate the performance of the model in two key ways- the F1 score or relaxed match:
1. F1 Score: The proportion of the number of shared words to the whole number of words in the prediction, and recall is the proportion of the number of shared words to the total number of words in the ground truth.
2. Relaxed Match: We estimate “relaxed match” by calculating performance based on the proportion of entity tokens identified as the correct entity type, regardless of whether the “boundaries” around the entity were correct.
For example, for a partial match: Say a model classifies “United States of America” as [B-LOC] [I-LOC] [O] [B-LOC], where the correct labels are [B-LOC] [I-LOC] [I-LOC] [I-LOC]. This would receive 75% credit rather than 50% credit. The last two tags are both “wrong” in a strict classification label sense, but the model at least classified the fourth token as the correct entity type.
Step #8: Using Generative AI as Entity validator
We used LLMs to resolve the tasks where it follows the general paradigm of in-context learning. The extracted entities are verified and confirmed to improve the precision of extracted contents. The process is decomposed into three steps:
Step 1: Prompt Construction- For a given input sentence X, we construct a prompt (denoted by Prompt(X)) for X.
Step 2: Few shot demonstration retrieval -Feeding the constructed prompt to the LLM to obtain the generated text sequence.
Step 3: Self-verification – Transforming the text sequence W to a sequence of entity labels to obtain the result.
Implementation Results
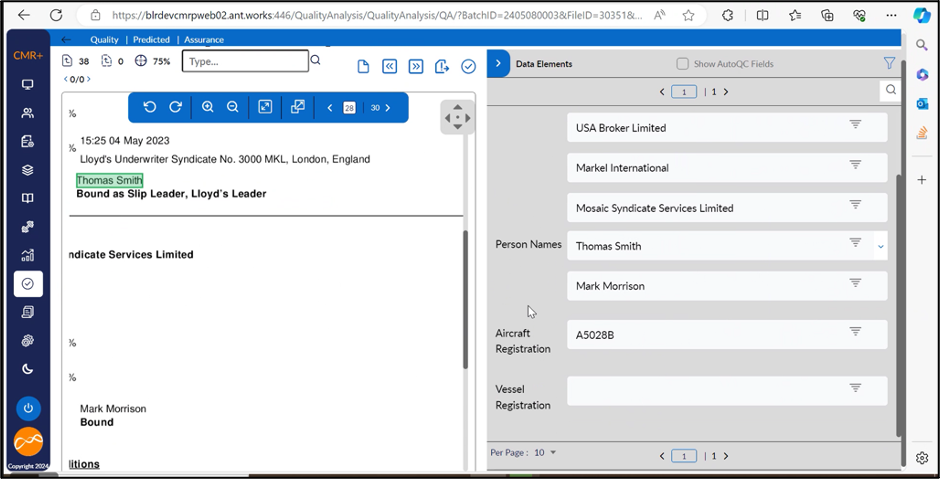
Scenario 1: Extraction with 100 % precision and recall
Entities extracted- Person names
The document in the display has a page size of 30. The expectation is to extract 2 person names present in the document. These were extracted with 100 % precision and 100 % recall.
Scenario 2: Extraction with high precision and recall achieved as a combination of BERT and LLM.
Entities extracted – Organization names
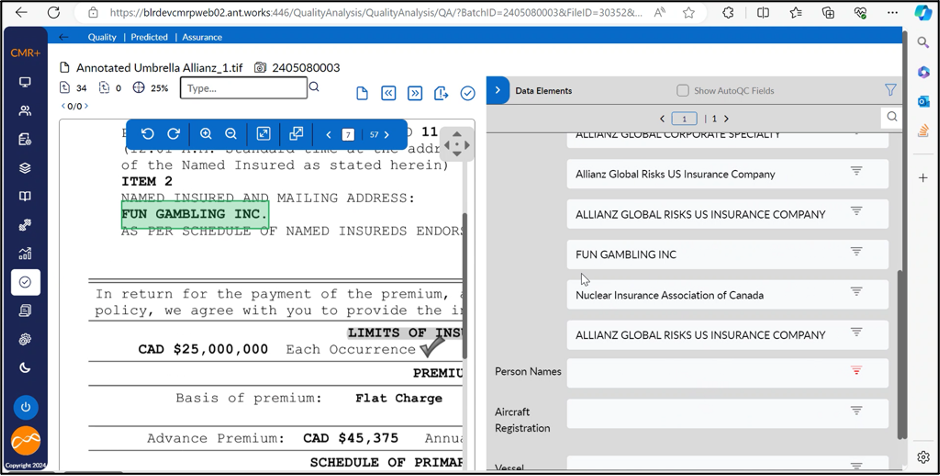
The document in the display has a page size of 57. The expectation was to extract 32 Organization names present in the document. These were extracted with 100 % recall and 80 % precision.
The evaluation metrices are as follows:
Total extractions | 40 |
True positive | 32 |
False positive | 8 |
False Negative | 0 |
True negative | 0 |
These results are again passed through LLM validator to verify whether the extracted entities are organization names or not. Post this, entities were extracted with 100 % recall and 94 % precision.
The updated metrics is as follows:
Total extractions | 40 |
True positive | 32 |
False positive | 2 |
False Negative | 0 |
True negative | 0 |
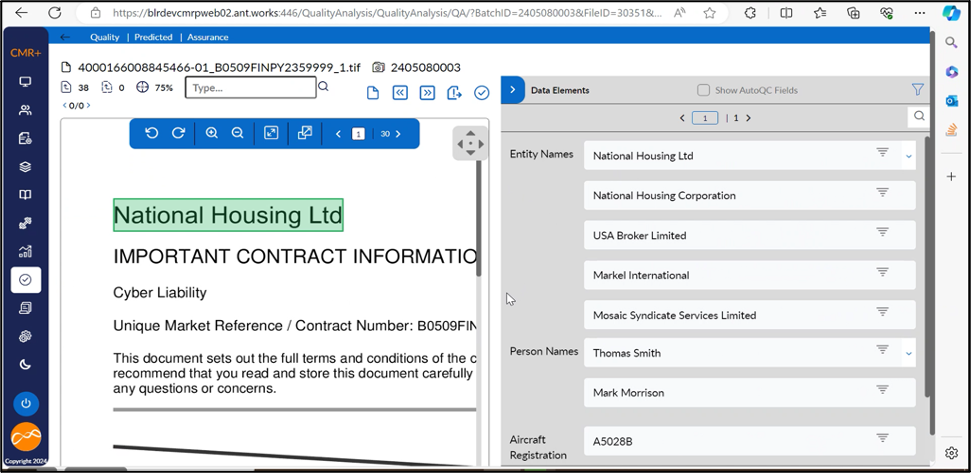
Scenario 3: Extraction with high precision and recall achieved as a combination of BERT and post-processing rules.
Entities extracted – Organization names
The document in the display has a page size of 30. The expectation is to extract 5 Organization names (Entity Names in display) present in the document. These were extracted with 100 % recall and 100 % precision. High precision is achieved by leveraging post-processing where rules are applied to finetune the extraction.
Some of the examples for post-processing rules are:
- Broker or insurer names should be excluded from the output.
- Enable duplicate entities when same entities have appeared in multiple pages
- Validate entities based on presence or absence of delimiters such as private, limited etc…
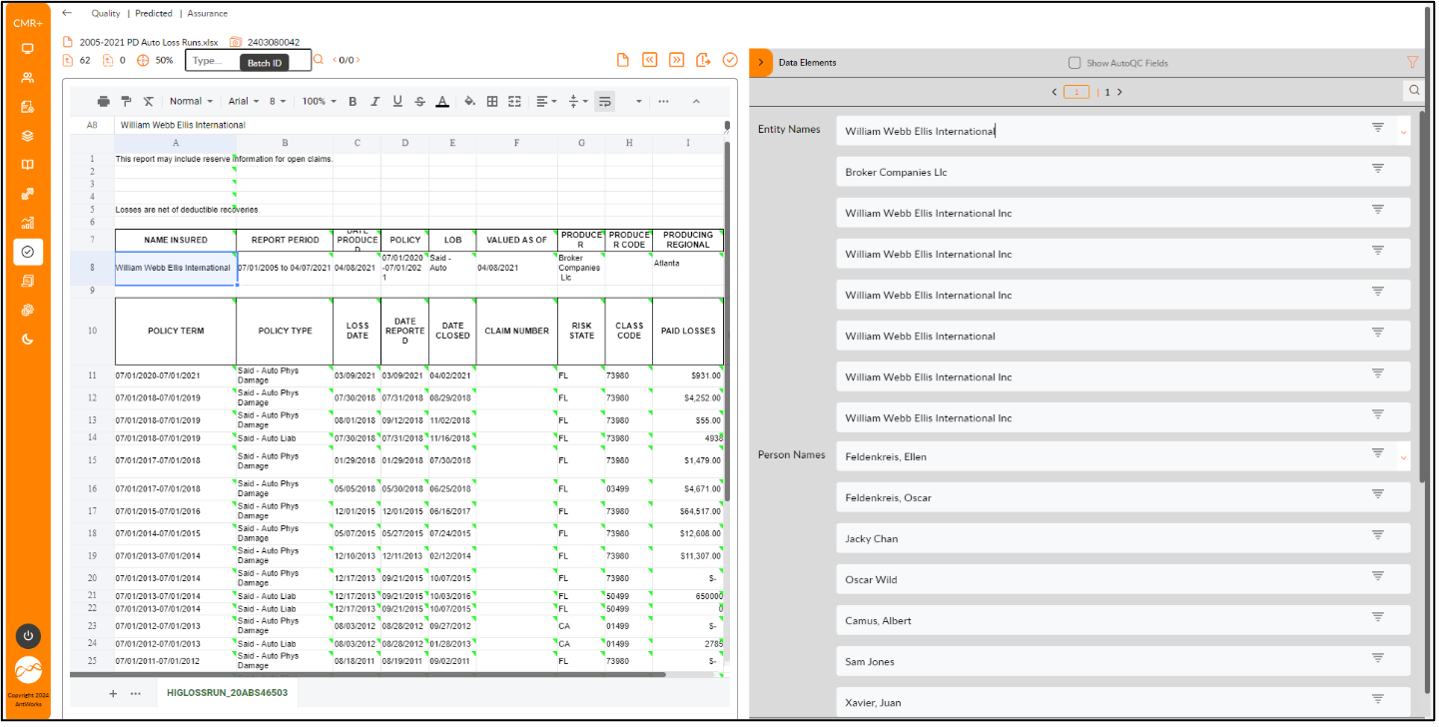
Scenario 4: Extracting from excel sheets
Entities extracted – Organization names and Person names
The excel display has 50 Organization names (Entity Names in display) and 35 Person names present. These were extracted with 100 % recall and 100 % precision. High precision is achieved as each cell is parsed and validated against the model. Excel parsing and extraction is implemented for all tabs available in excel.