Missed Part 1?
Click here to catch up on the challenges and innovations driving our patented approach to data extraction.
In Part 1, we explored the limitations of traditional methods, the growing need for adaptable solutions, and how our approach mimics human-like understanding to overcome these challenges.
6. The approach: How It works
The proposed approach follows a structured workflow that ensures data is captured accurately and efficiently.
Document intake
This phase involves initial document processing and setting extraction parameters, with three key inputs:
- Input Documents -Various document types like policies, mortgages, contracts, and claim forms for data extraction.
- Field Characteristics: Predefined details about fields of interest, including formats, length, location, layout, and any necessary transformation rules.
- GT (Ground Truth): Manually labeled or verified data used as a reference for training the model.
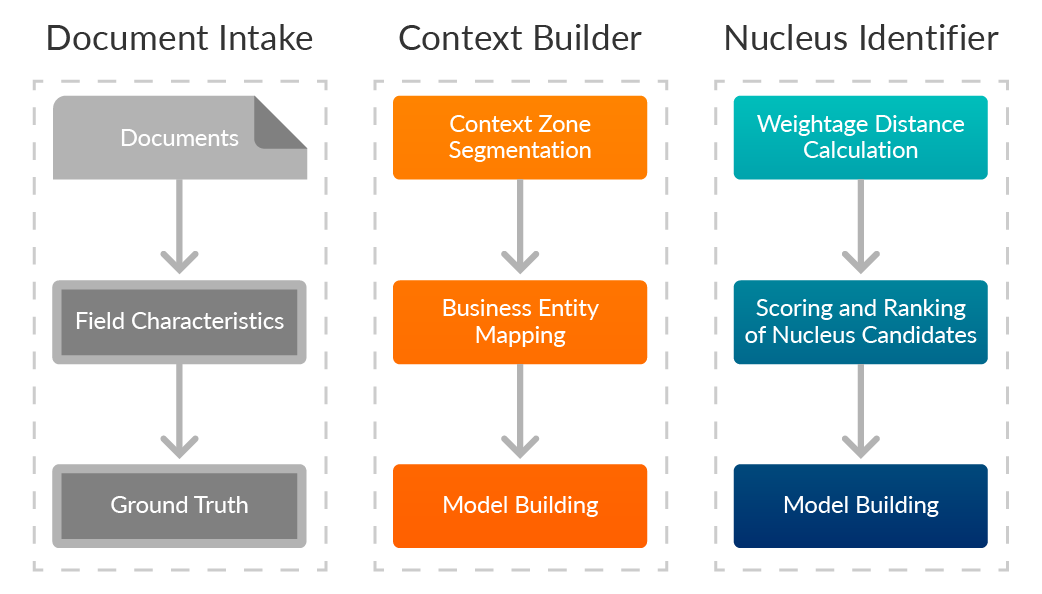
Context builder
The Context Builder enhances data capture by defining relevant sections or “context windows” within documents using location-based constraints and training data for precise identification. Below is a breakdown of the technical process behind the Context Builder:
- Identify potential context windows: The system scans the document to find zones that meet location constraints, such as proximity to key data points, for content extraction.
- Scan zones across location constraints: The system analyzes zones based on their spatial relationship to key elements, checking for distance between clusters, alignment, and proximity to domain anchors like headers or labels.
- Create parameters: The system generates scoring parameters based on spatial features (positions, distances, alignment), semantic content (e.g., numeric or textual), and document patterns (e.g., tables, lists).
- Perform supervised learning on samples: A supervised learning model is trained on labeled samples to predict the viability of context windows, differentiating relevant zones and ranking them based on task relevance.
- Match score calculation: Each zone is assigned a viability score based on its similarity to training patterns, reflecting its likelihood to contain desired data.
- Determine threshold based on ROC Elbow: The system uses the ROC curve to identify the optimal precision-recall balance, setting a threshold score at the “elbow point” for fine-tuned extraction.
Data nucleus identification
Data Nucleus identification is a key step in the system’s extraction process, where the region of interest (ROI) is prioritized to capture critical information, using a weighted distance calculation to determine the optimal extraction zone and reduce irrelevant data. The steps are:
- Identification of nucleus candidate: The system scans the document to identify candidate regions based on contextual markers, spatial relationships, and content patterns relevant to the document’s structure.
- Weighted distance calculation: The system calculates a weighted distance for each candidate, considering proximity to anchor points, content relevance, and spatial alignment/density for accurate extraction.
- Scoring and ranking of nucleus: Each candidate nucleus is scored based on its likelihood to contain critical data, with regions ranked accordingly.
- Selection of data nucleus: The system selects the highest-ranked nucleus for extraction, ensuring optimal accuracy and efficiency in data capture.
Dynamic adjustment based on feedback
The approach can further refine the selection of the data nucleus through user feedback and iterative learning. If a region is consistently found to contain more critical data, the system adjusts its weighted distance calculation for future documents, enhancing accuracy over time.
Prediction
The diagram presents a Prediction workflow that highlights the sequential steps involved in identifying and validating critical data from documents. Here’s a breakdown of each component:
Document intake
This phase involves the initial document processing and setting up the parameters for extraction. It contains two key inputs:
- Input Documents: These are the documents or files that will undergo processing.
- Field Characteristics: This refers to predefined information about the field.
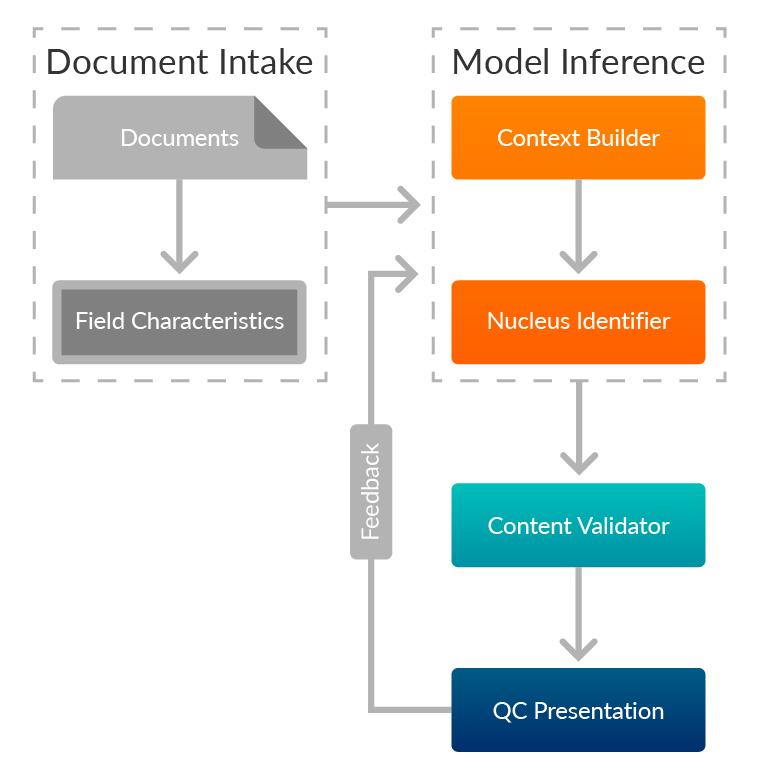
Context builder
The Context Builder is responsible for identifying potential areas or zones in the document where the desired information might be located. Based on spatial and textual patterns, it predicts candidate contexts or regions within the document that likely contain the target data.
Nucleus identifier
The Nucleus Identifier refines the work done by the Context Builder by pinpointing the exact area or nucleus where the critical data is likely to reside.
Content validator
This step verifies that the content within the predicted nucleus is accurate, contextually relevant, and follows expected formats, such as proper date or numeric patterns.
QC presentation
The QC Presentation displays the extracted and validated content to the user, ensuring the extracted data meets quality standards before being finalized.
Feedback collection
Users or reviewers can provide feedback on the accuracy of extracted content, highlighting errors or missed regions. This feedback is used to train the system, improving the Context Builder and Nucleus Identifier for more accurate future extractions.
7. Conclusion
The proposed approach for identifying content in documents represents a breakthrough in data capture technology. By mimicking human cognitive processes, this adaptable and efficient system excels in extracting data even from unstructured or complex documents. It continuously learns through user feedback, refining its accuracy with minimal human intervention, and eliminates dependency on fixed document structures, making it highly flexible across different formats.
This innovative approach not only enhances accuracy and efficiency but also empowers organizations to gain deeper insights from their documents. Automating data extraction and reducing manual effort enables businesses to streamline operations, make faster, more informed decisions, and maintain a competitive edge. The system’s ability to learn and evolve ensures it remains relevant and effective, even as document types and business needs change.
As document extraction evolves, the proposed approach has promising potential for future advancements. It could expand into multi-lingual, language-agnostic processing, leverage transfer learning for adaptability across domains, and maintain its robust context identification while integrating generative AI for deeper extraction, using the context builder as a reliable guardrail for focused data capture.
Did you find this blog insightful?
Share it on LinkedIn and let your network join the conversation!
